HTTP/1.0
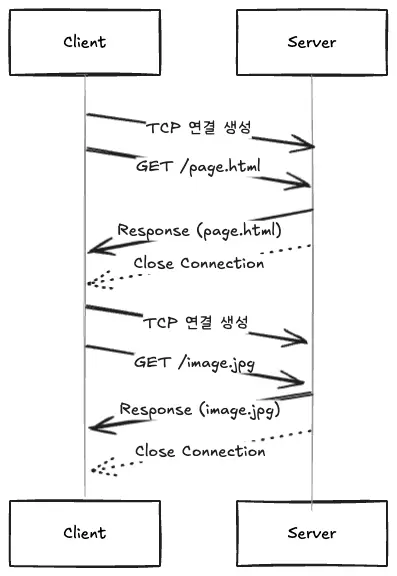
HTTP/1.0 used the Short-lived Connection model, where the client had to establish a new TCP connection for each resource (HTML, css, image, js) request. In other words, it created one connection per request.
HTTP/1.1
HTTP/1.1 was introduced to address these shortcomings.
HTTP/1.1 introduced the concept of Persistent Connection or “Keep-Alive”. **This reduces the overhead of handshakes by reusing a single TCP connection for multiple requests.
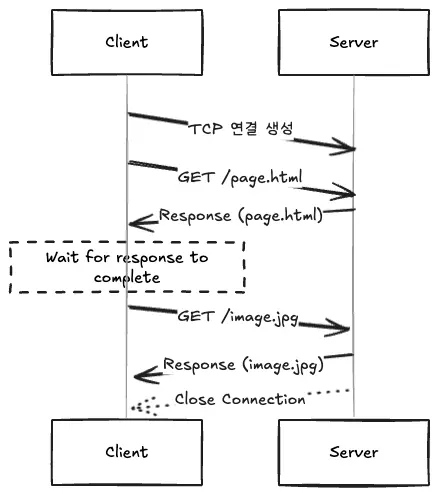
However, this model was still problematic. The client could only send the next request after receiving all the responses to one request, which introduced a new bottleneck of idling TCP connections.
Pipelining
HTTP pipelining was designed to solve this idle time problem. It is the ability for a client to send multiple requests at once without waiting for a response from the previous request. The goal is to reduce idle time and latency by keeping the network pipes filled with data at all times.
How pipelining works
Pipelining was designed to overcome the limitations of the sequential request-response model.
Prerequisites
- Persistent connections:** Only works over persistent connections (
keep-alive). - Idempotent methods:** You can only pipeline idempotent methods, such as GET, HEAD, PUT, and DELETE, that have the same result when sent multiple times. This is because in the event of a network error, the client doesn’t know which requests succeeded, so the entire batch of requests must be safely retransmitted. Non-equivalent methods, such as POST, are prohibited due to the problem of generating duplicate data.
Mechanisms
- The client establishes a
keep-aliveTCP connection with the server. - the client sends multiple requests in sequence without waiting for a response.
- the server sends responses in exactly the same order as it received the requests. This first-in, first-out (FIFO) principle must be honored.
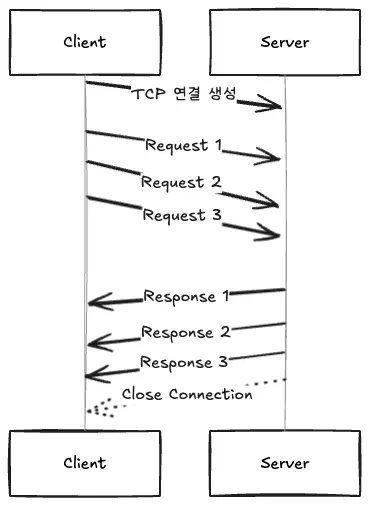
This pipelining technique minimizes network latency by allowing multiple requests to be sent within a single RTT, reduces the idleness of TCP connections, and makes efficient use of network resources by allowing multiple requests to be sent in a single TCP packet.
However, pipelining has a fatal flaw: Head-of-Line (HOL) blocking.
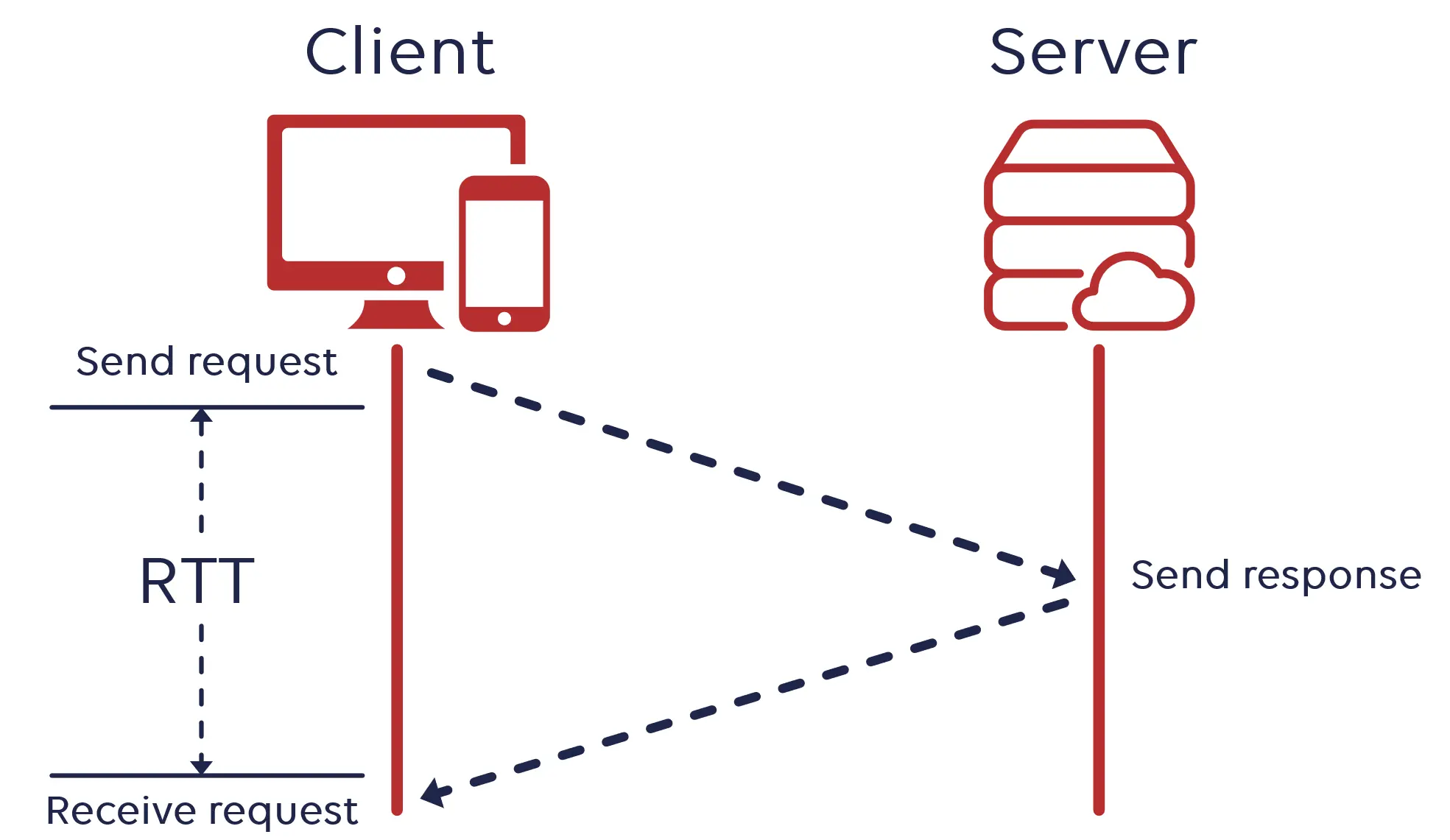
RTT stands for Round Trip Time, which is the time between sending a request (SYN) and receiving a response (SYN+ACK) to the request in a TCP handshake.
HOL Blocking
As mentioned earlier, in pipelining, the server sends responses in exactly the same order as it received requests. Because HTTP/1.1 had no mechanism to uniquely identify each request and response, it had to process them in the exact same order to ensure that the right response was sent to the right request.
So if the earliest item in the queue is delayed in processing, everything behind it has to wait, causing HOL blocking.
Suppose a client sends three requests to pipelining in sequence.
GET /api/complex_report(takes 5 seconds)GET /images/logo.png(takes 10ms)GET /css/styles.css(takes 10ms)
The server prepares the logo and CSS files immediately, but because of the first-in, first-out rule, it can’t send a response and has to wait until the report generation is complete, which takes 5 seconds. In the end, it takes more than 5 seconds to get the logo image, so the pipelining actually worsens the user experience.
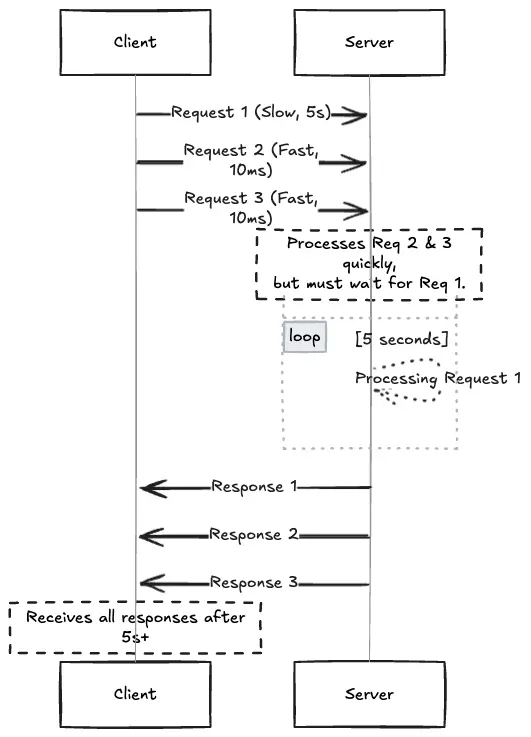
This is an application layer issue inherent in the HTTP/1.1 protocol itself, and it was impossible to fix. Reordering responses requires a way to identify each response, which HTTP/1.1 did not have.
HTTP/2.0 came along to fix this problem.